
Érdekesség: újabb de-anonimizációs támadás közösségi hálózatok ellen
Még 2009-ben publikáltak kutatók egy hatékony közösségi hálózatokat de-anonimizáló algoritmust (mi is írtunk róla). A módszerük ún. passzív de-anonimizáló támadás, ami azt jelenti, hogy az anonimizálási folyamat előtt nem próbálják meg módosítani a közösségi hálót, hanem ehelyett egy kiegészítő információforrás segítségével hajtják végre a de-anonimizációt. Az eredeti algoritmusban ez egy másik közösségi hálózatot jelentett; konkrétan egy ismert Flickr és anonimizált Twitter gráfra hajtották végre a támadást, amelynek eredményeképp a felhasználók 31%-át sikerült újra azonosítani a Twitter gráfban. Most egy újabb ötlettel ismerkedhetünk meg.
A támadás mögötti fő elv lényege – a szerzők szerint –, hogy a különféle hálózatok csupán leképzései egy mindenek felett álló "közösségi hálózatnak", amit a hétköznapi életben meglévő kapcsolati rendszerben találunk meg. A 2009-ben publikált támadásban tehát ezeket az – mindkét hálózatban jelenlévő, a leképzést "túlélő" – éleket találták meg. A mostani támadás pedig a másik véglettel foglalkozik, amikor az anonimizált közösségi hálózat és a kiegészítő információként használt is ugyanaz, csak más időszakból származik. (A felhasználási területe is speciális, ugyanis egy versenyben kiadott hálózatot de-anonimizáltak a győzelem érdekében; további részletek a cikkükben.)
Mind a 2009-ben és az idén publikált támadás nagyon hasonló, két fő fázisból áll:
- Magkeresési fázis. Az algoritmus ebben a fázisban először keres néhány olyan csomópontot a két hálózatban, amelyek összeköthetőek, azaz amelyek egymásnak nagy valószínűséggel megfeleltethetőek. Ez lesz a kiindulási mag, ebből a halmazból indul tovább a terjedési fázis.
- Terjedési fázis. Iteratív fázis, amelyben a meglévő halmazt próbálja az algoritmus bővíteni egy újabb egymáshoz rendelt csomópont párral.
A két algoritmus leginkább a magkeresési fázisban tér el. A korábbi algoritmus itt egyedi 4-es klikkeket keresett és próbált meg egymáshoz rendelni a strukturális tulajdonságaik alapján (csomópontok fokszámai, közös szomszédainak számai). Erre látható az alábbi illusztráció, amiben kiemeltünk két összepárosított 4-es klikk.
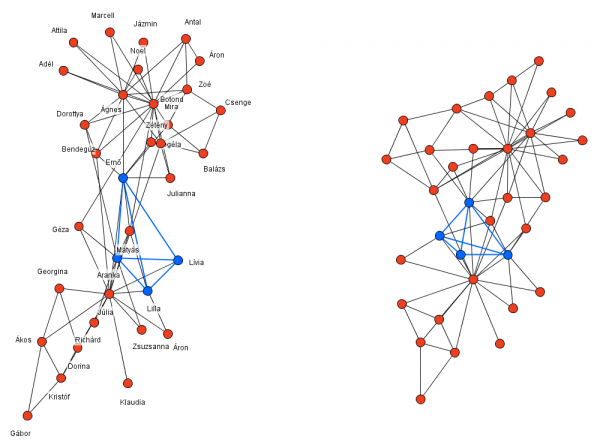
Egy anonimizált (jobbra) és egy kiegészítő információként használt (balra) közösségi hálózat gráfjai. A korábbi algoritmusnak megfelelően két 4-es klikk van kiemelve, amelyek egymásnak feleltethetőek meg.
Az új algoritmus ennél rugalmasabb, és két k csomópontból álló halmaz elemei között keres átfedést. Mivel ez már önmagában erőforrásigényes probléma, és nagyon sok k méretű halmaz képezhető egy hálózatban, ezért a szerzők a fokszámok szerinti felső k csomópontot javasolják kiválasztásra – ez érthető választás, hiszen ezek a csomópontok a legegyedibbek a hálózatban. Ezek után az algoritmus a k méretű halmazon belül párokat képez, és minden párra egy értéket számol a strukturális jellemvonásaik alapján, majd a két halmaz párjai között a hasonló értékek szerint párosítást hoz létre.
Az algoritmus szakmai szempontból nagyon érdekes, és elég ötletes a benne használt hasonlósági mérték is. Ami viszont a cikkből nem derül ki, és elég fontos kérdés: ha nem ugyanannak a hálózatnak két állapotát támadjuk ezzel a módszerrel, a felső k csomópont kiválasztása akkor is működni fog? Amíg ezt nem látjuk igazolva, addig véleményem szerint nem tekinthetjük ezt az algoritmust általánosságban használhatónak (szemben a korábbi algoritmussal).
Hozzászólások
Összesen 0 hozzászólás látható.
Nincsenek hozzászólások.
Új hozzászólás beküldése
Bárki hozzászólhat, nem regisztrált beküldő esetén egyik adat megadása sem kötelező - a hozzászólás akár névtelen is lehet.

